Spatiotemporal Variance-Guided Filtering (SVGF)
Introduction
SVGF is a filtering technique that turns a noisy input and reconstructs it into a full image. This technique normally takes about 10ms to run, so integrating it into a real-time raytracer might not be beneficial. Deep-learning filters can probably accomplish something similar in a lot less time. However, this technique is very good at reconstructing the final image, especially the tweaked version (A-SVGF (adaptive SVGF)). “When compared to prior interactive reconstruction filters, our work gives approximately 10x more temporally stable results, matches reference images 5-47% better (according to SSIM), and runs in just 10ms (+- 15%) on modern graphics hardware at 1920x1080 resolution.” - NVIDIA.
Estimation
I estimate that implementing all of this correctly would require to understand the entire code, which in total could definitely fill up around 5 weeks to 8 weeks. Implementing the code could take less time, but that’s if you only go for implementation and not improving it and/or modifying it. A-SVGF is a newer technique, which builds on this and improves it, removing issues like flickering. This also doesn’t have examples, so implementing it would require even more time.
Implementation
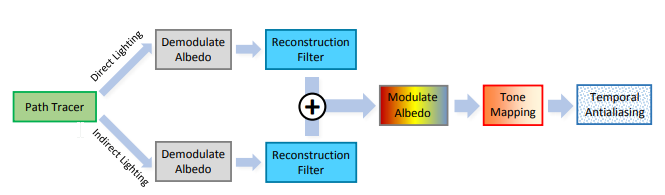
The path tracer / raytracer provides you with direct and indirect lighting. This goes through a reconstruction filter and gets combined. Afterwards, tonemapping and TA is applied to the result. (In our case, we could replace it with tonemapping + DLSS).
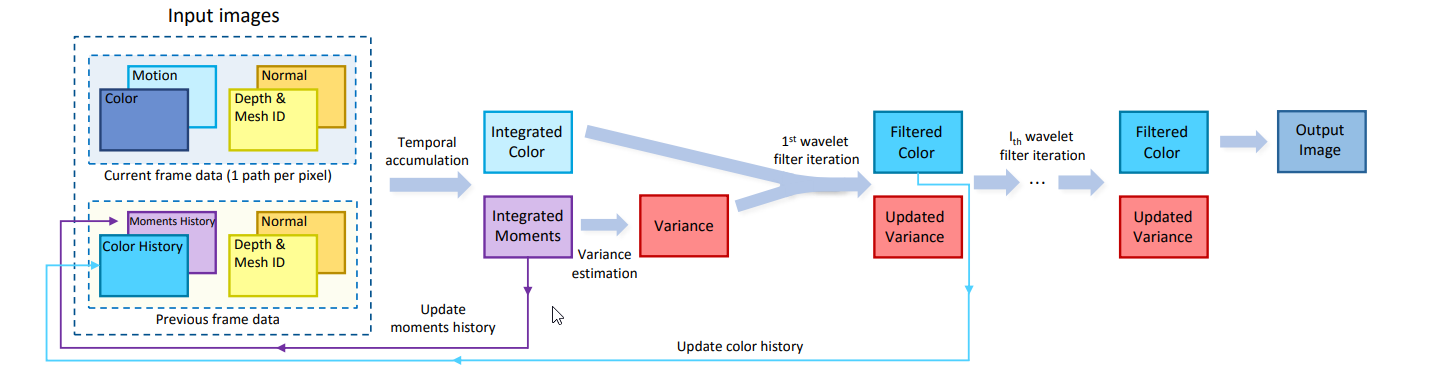
The reconstruction filter is shown above; it uses temporal accumulation to determine the integrated color/moments and variance estimation to get the filtered color.
All of this means that we require history buffers (from prior frame reconstruction) and we need rasterization to provide us with normal, albedo, depth, motion vectors and mesh id.
This implementation is difficult, however, there’s already example code out there (or a copy on our drive). This makes it way easier to read, instead of having to create your own code from math formulas.